Conversational Image Generation: Towards Multi-Round Personalized Generation with Multi-Modal Language Models
Abstract
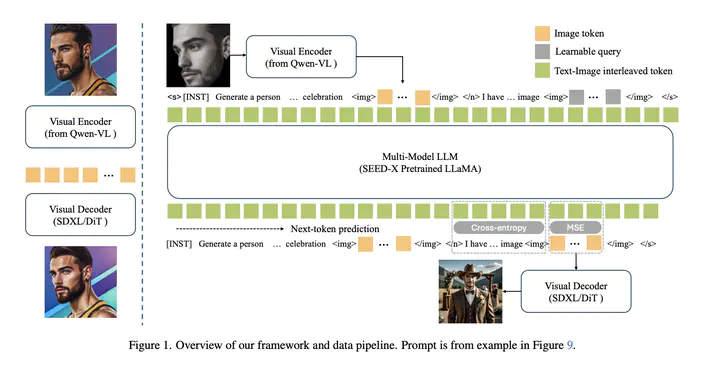
Recent advancements in diffusion models have significantly enhanced personalized image generation, enabling high-fidelity synthesis of human-subject-specific images. However, existing approaches are constrained by the inherent limitations of diffusion models, which lack conversational capabilities, and operate in a single-round setting, restricting user interaction. In this work, we propose a novel framework that integrates multi-modal large language models (MLLMs) for multi-round conversational personalization. To achieve this, we identified a performance bottleneck in the detokenizer of current MLLMs, which struggles to reconstruct fine-grained facial identity details. Thus, we enhance the detokenizer with a personalization-enhaced Diffusion Transformer (DiT). We also introduce a multi-stage instruction fine-tuning strategy to balance face preservation and prompt alignment effectively. To support multi-round generation, we implement a chat-history caching mechanism and construct the first multi-round personalization dataset from video clips. Experimental results demonstrate that our approach achieves state-of-the-art performance among MLLM-based personalization methods. To the best of our knowledge, this is the first work to enable conversational personalization, unlocking new capabilities for MLLMs in personalized image generation.
Animesh Sinha
Research Engineer
My research interests include Generative AI, Computer Vision and Multimodal Understanding.